Rows: 44
Columns: 11
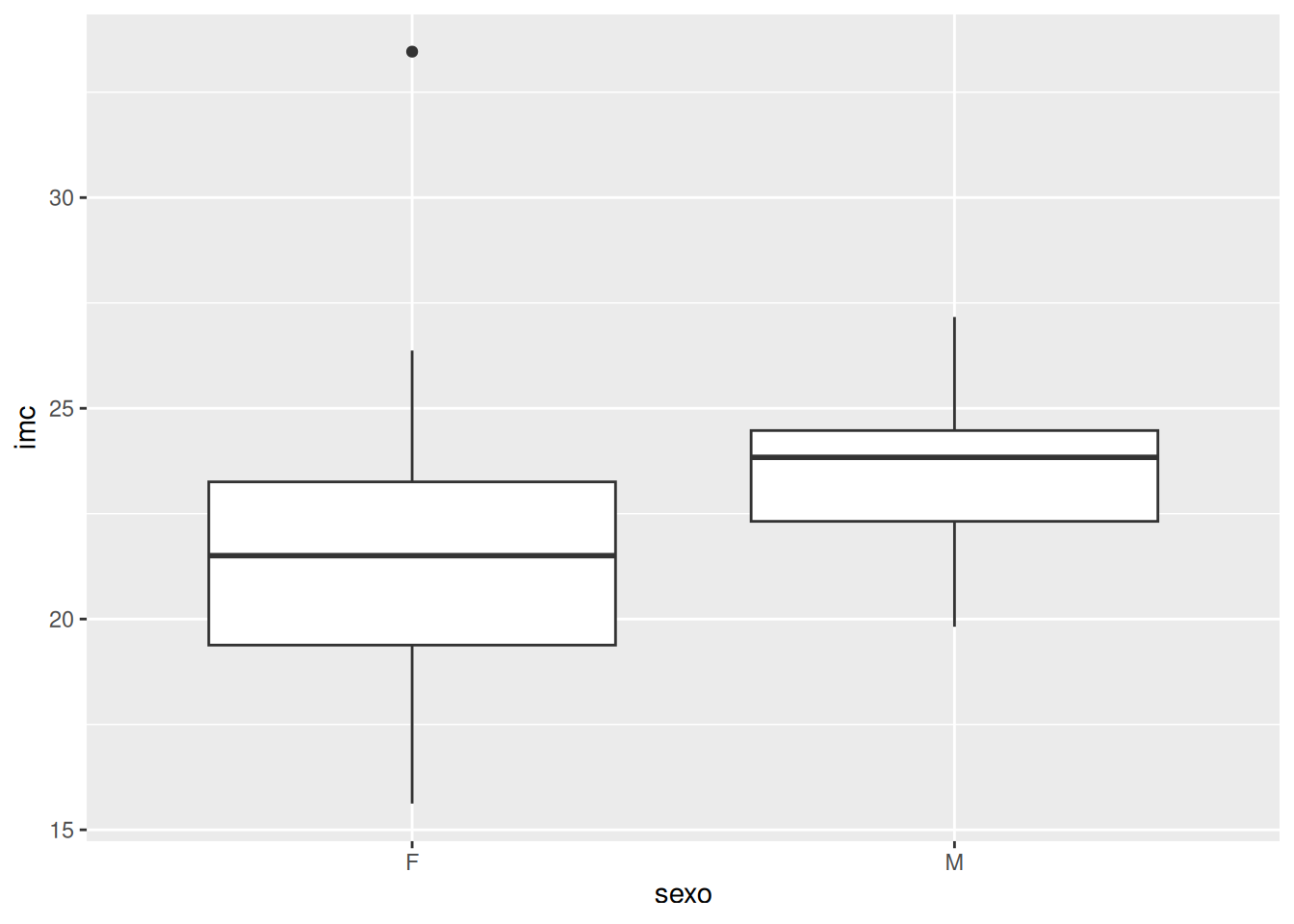
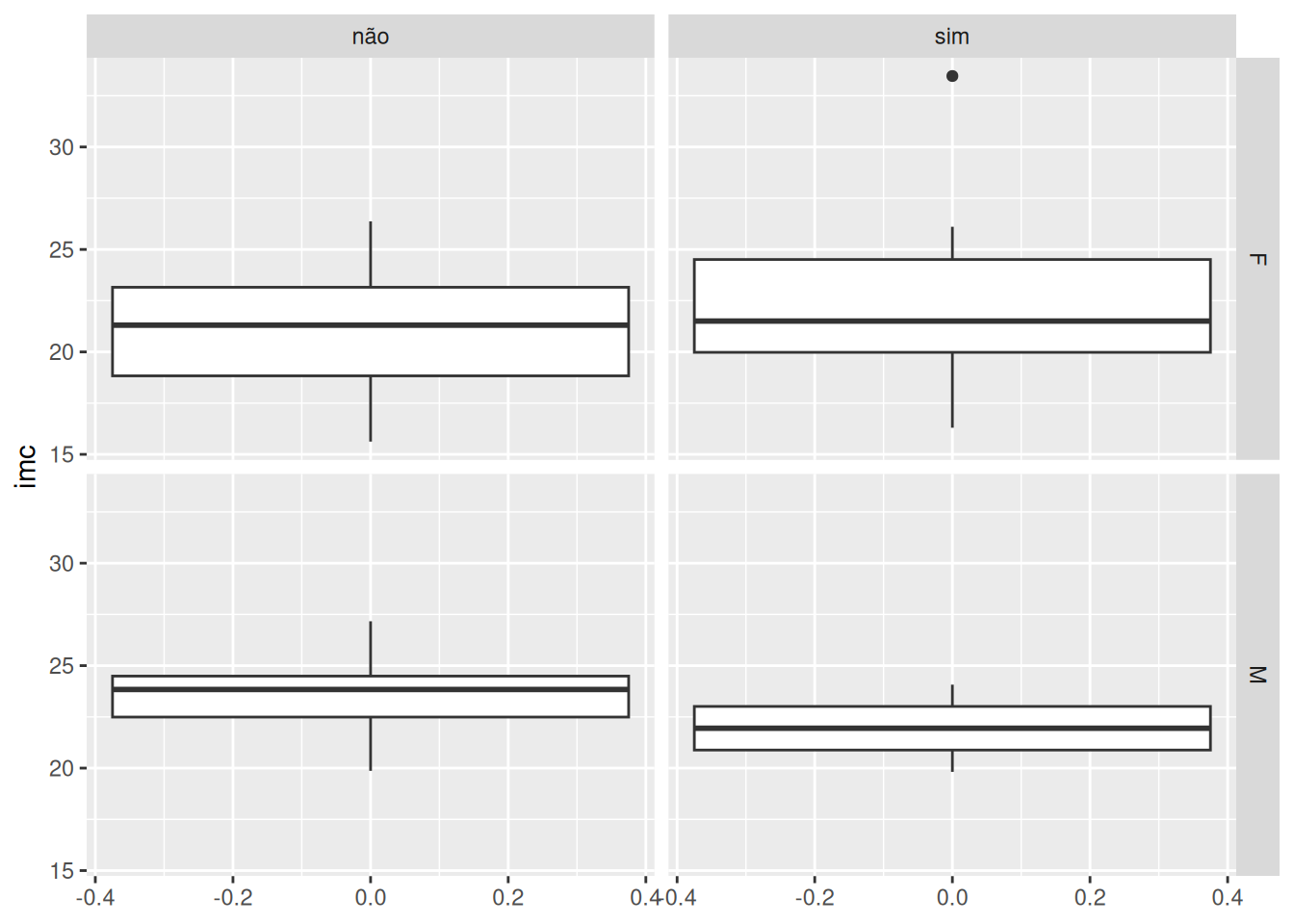
$ sexo <fct> M, M, F, F, M, F, F, M, F, F, F, F, F, F, F, F, F, F, F,…
$ idade <int> 34, 17, 19, 22, 18, 22, 18, 21, 18, 18, 20, 21, 18, 17, …
$ peso <int> 75, 89, 48, 48, 58, 64, 52, 75, 56, 46, 64, 60, 66, 67, …
$ altura <dbl> 1.72, 1.81, 1.54, 1.55, 1.54, 1.56, 1.55, 1.75, 1.65, 1.…
$ alimentacao <chr> "sim", "não", "sim", "não", "sim", "sim", "não", "sim", …
$ frutas <int> 1, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 1, 1, 4, 3, 2, 3, 1, 4,…
$ vegetais <int> 2, 4, 4, 4, 1, 2, 4, 1, 1, 2, 1, 2, 2, 2, 2, 6, 3, 6, 2,…
$ sedentarismo <chr> "não", "não", "não", "sim", "não", "não", "sim", "não", …
$ tempo <chr> "entre 2 e 5 horas", "entre 5 e 10 horas", "entre 2 e 5 …
$ imc <dbl> 25.35154, 27.16645, 20.23950, 19.97919, 24.45606, 26.298…
$ classificacao <fct> "(25,30]", "(25,30]", "(18.5,25]", "(18.5,25]", "(18.5,2…